Eynollah

Document Layout Analysis with Deep Learning and Heuristics
The document layout analysis with Eynollah supports up to 10 segmentation classes, as well as various image optimization operations (deskewing, etc.). In order to improve OCR, Eynollah is also able to detect the reading order.
A link to the software, as well as more information, can be found here.
Image search
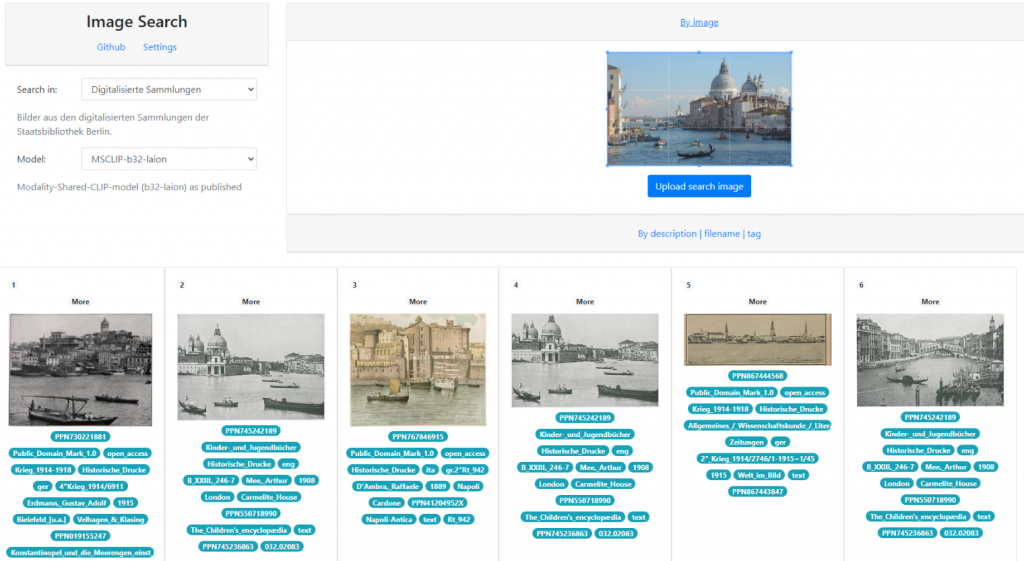
Image Search of the Berlin National State Library
This software lets you implement your own image similarity search. It utilizes different search parameters like textual descriptions, images, and Iconclass labels. Furthermore, the search supports different features like tagging images, which in turn can be used to train an image classifier. The software is not just compatible with the image classifier, but also with the following region annotator.
A link to the software, as well as more information can be found here.
Region annotator
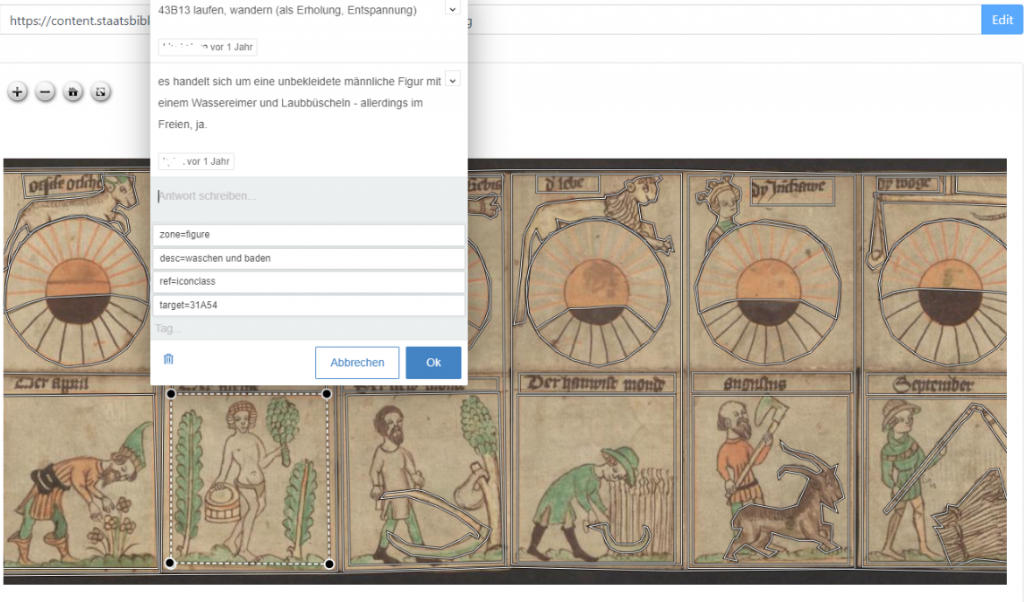
An Image Region Annotation Tool Based on Annotorious OpenSeadragon
This tool was created to enable collaborative annotation of images and only requires access to the images via HTTP/HTTPS URLs. There is no need for a separate database, since backups of the entire annotation data are possible via the web interface.
A link to the tool, as well as more information can be found here.
Image classifier
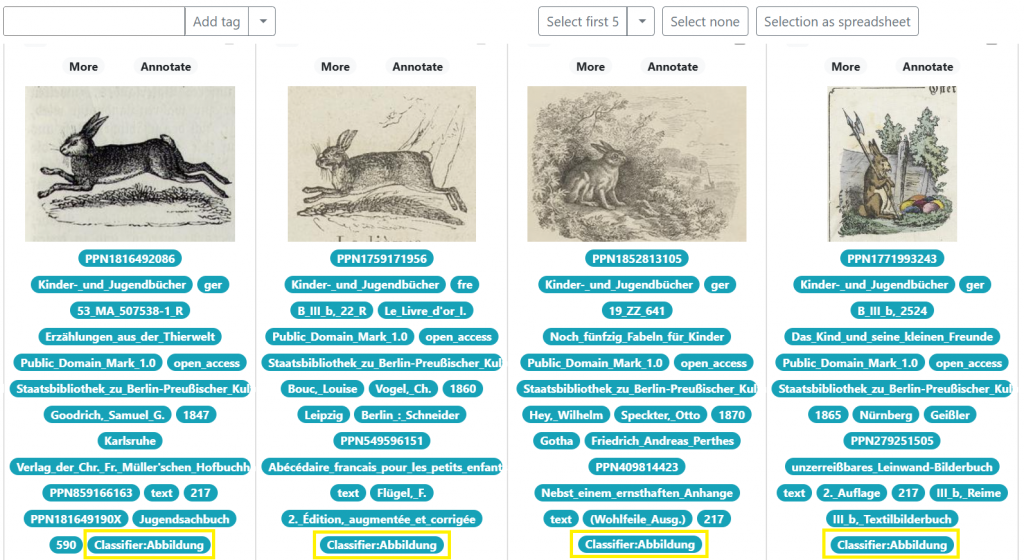
Image classifier for the Image Search of the Berlin National State Library
This tool enables users to train an image classifier based on the previously tagged images. These can be tagged using the image search interface or the single label annotator.
A link to the tool, as well as more information can be found here.
Tool for Named Entity Recognition (NER)
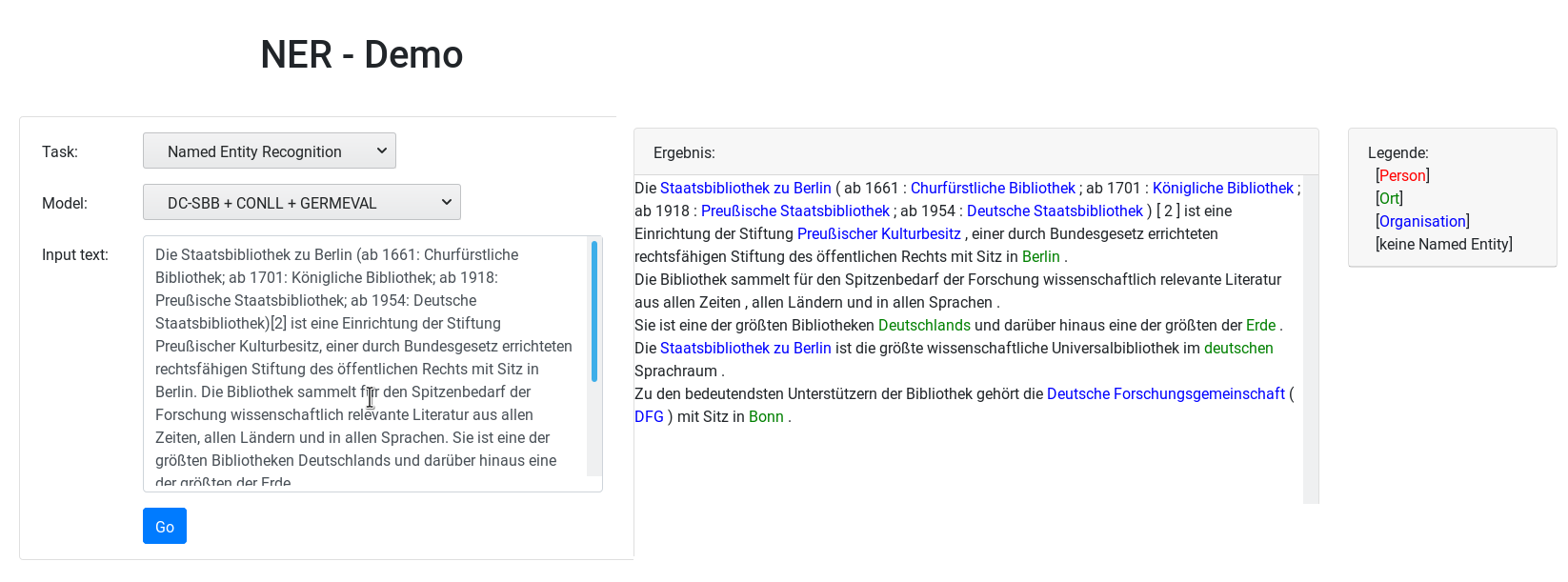
A Tool based on a BERT model trained on three German corpora containing contemporary and historical texts for named entity recognition tasks. It predicts the classes PER (Person), LOC(Location) and ORG(Organisation).
A link to the tool, as well as more information can be found here or on huggingface.
NER Tool with Huggingface Transformers
The sbb_ner_hf tool uses the HuggingFace Transformers library and offers the possibility of modularly fine-tuning a large number of pre-trained language models already contained in HuggingFace to the NER task for German-language, historical newspapers on the basis of data sets prepared for this purpose.
A link to the tool, as well as more information can be found here or on huggingface.
Models for semi-automatic subject indexing
5 Annif models, trained on historical titles and additional catalogue metadata for automatic subject indexing tasks. It classifies a given text into one or multiple subjects from the “Alter Realkatalog” (ARK) classification system.
A link to the models, as well as more information can be found on huggingface.
Transformer-based OCR model

TrOCR is a Transformer-based OCR model for text recognition. It uses the Transformer architecture for both image recognition and text generation at the word level. CNN/RNN models were previously used for these steps, but new Transformer-based models have higher text recognition accuracy.
A link to the software found here.