Eynollah

Layoutanalyse historischer Texte mit Deep Learning und Heuristiken
Die Layoutanalyse mit Eynollah erkennt bis zu zehn verschiedene Elemente bzw. Inhaltsbereiche in historischen Dokumenten. Um die Qualität der anschließenden Texterkennung (OCR) zu verbessern, identifiziert Eynollah außerdem die korrekte Reihenfolge der Textregionen (Reading Order Detection).
Die Software, sowie weitere Informationen dazu finden Sie hier.
Bildsuche
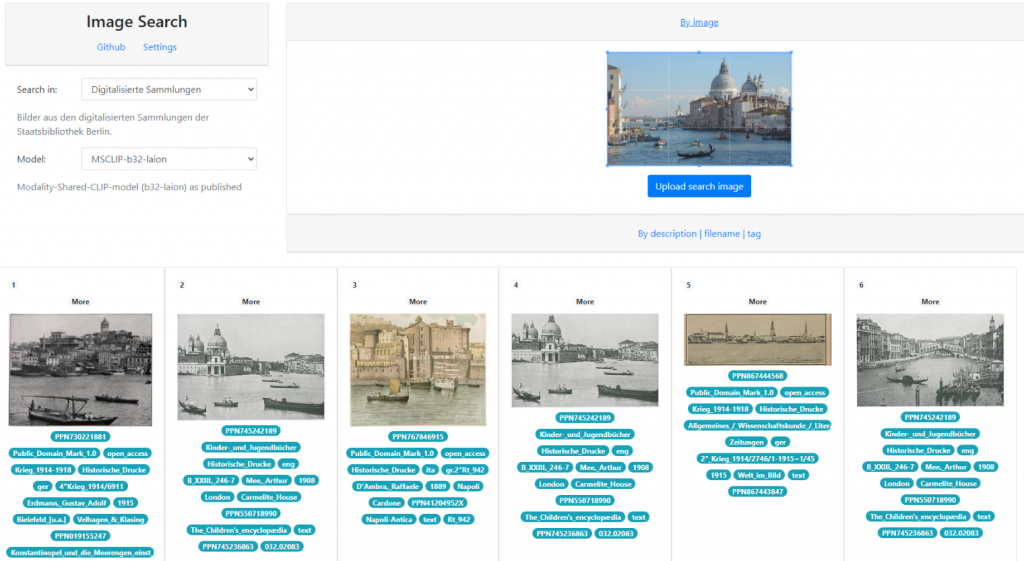
Bildsuche der Staatsbibliothek zu Berlin
Diese Software ermöglicht den Aufbau einer Bildähnlichkeitssuche, die verschiedene Suchmodalitäten unterstützt – etwa die Suche nach ähnlichen Bildern, auf Basis eines Beschreibungstextes oder mithilfe von Iconclass-Klassifikationen. Weitere Features der Suche sind das taggen von Bildern, welche genutzt werden können um einen Bildklassifikator zu trainieren, oder die Kompatibilität mit dem Regions-Annotations-Tool.
Die Software, sowie weitere Informationen dazu finden Sie hier.
Bild Klassifikator
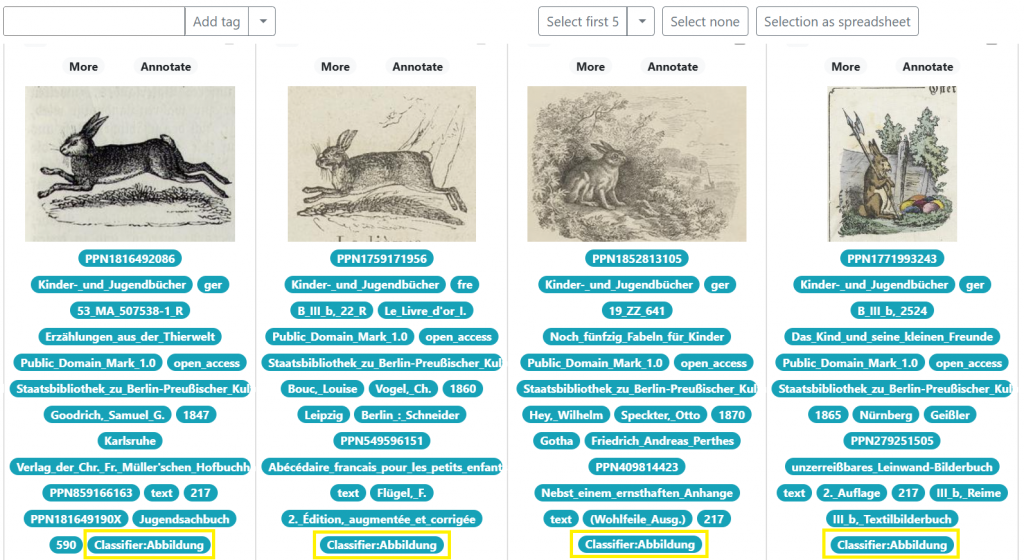
Bild Klassifikations-Tool für die Bildsuche der Staatsbibliothek zu Berlin
Mit diesem Tool kann ein Klassifikator für die automatische Bildklassifikation trainiert werden. Voraussetzung ist eine ausreichend große Menge zuvor annotierter Bilder.
Das Tool, sowie weitere Informationen dazu finden Sie hier.
Regionsannotator
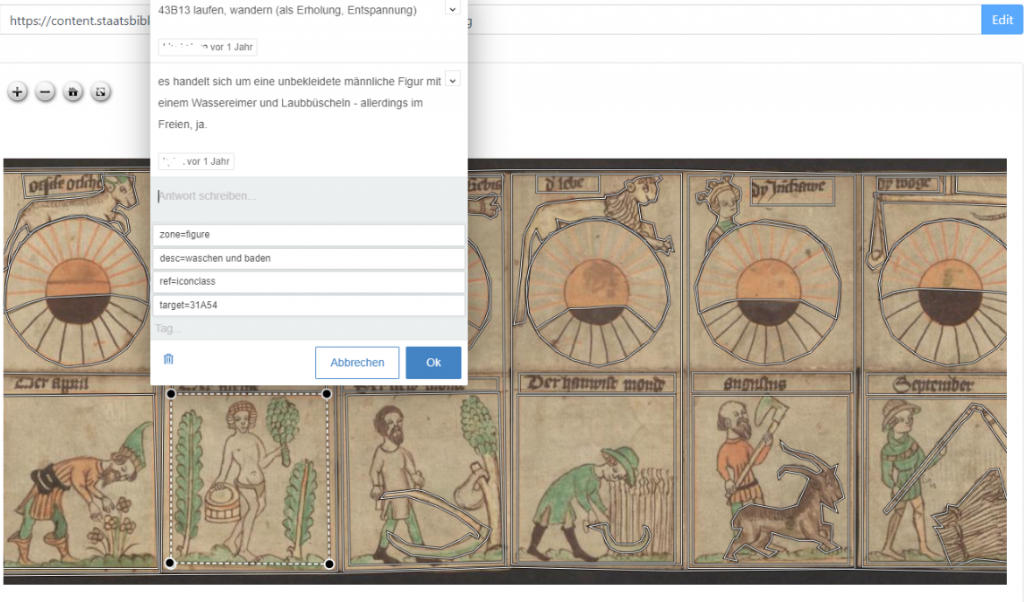
Ein Bildannotationstool auf der Basis von annotorious openseadragon
Dieses Tool wurde für die kollaborative Annotation von Bildern entwickelt. Der Zugriff auf die Bilder über HTTP- oder HTTPS-URLs ist ausreichend. Es sind keine separaten Server zur Speicherung der Annotationen erforderlich, da Backups direkt über das Webinterface möglich sind. Diese Tool ist mit der SBB Bildsuche Software kompatibel.
Das Tool, sowie weitere Informationen dazu finden Sie hier.
Tool für Named Entity Recognition (NER)
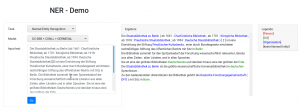
Das Tool basiert auf einem BERT-Modell, das auf drei deutschen Korpora mit zeitgenössischen und historischen Texten für Aufgaben der Named Entity Recognition trainiert wurde. Es sagt die Klassen PER (Person), LOC (Location) und ORG (Organisation) voraus. Dieses Modell wurde im Curator Projekt erstellt und im Mensch.Maschien.Kultur Projekt weiter verbessert.
Das Tool, sowie weitere Informationen dazu finden Sie hier oder auf huggingface.
NER Tool mit Huggingface Transformers
Das sbb_ner_hf Tool nutzt die HuggingFace Transformers library und bietet die Möglichkeit, modular eine Vielzahl an bereits in HuggingFace enthaltenen vortrainierten Sprachmodellen auf der Grundlage hierfür aufbereiteter Datensätze auf den NER Task für deutschsprachige, historische Zeitungen feinabzustimmen.
Das Tool, sowie weitere Informationen dazu finden Sie hier oder auf huggingface.
Modelle für die semi-automatisierte Sacherschließung

5 Annif Modelle für die semi-automatisierte Sacherschließung
Die Annif-Modelle, welche für die semi-automatisierte Sacherschließung genutzt werden können, wurden auf historischen Titeln und zusätzlichen Katalog-Metadaten der Staatsbibliothek zu Berlin trainiert. Sie klassifizieren einen gegebenen Text in ein oder mehrere Fächer aus dem Klassifikationssystem „Alter Realkatalog“ (ARK).
Die Modelle, sowie weitere Informationen dazu finden Sie auf huggingface.
Transformer-basiertes OCR-Modell

TrOCR ist ein Transformer-basiertes OCR-Modell zur Texterkennung. Es nutzt die Transformer-Architektur sowohl für die Bilderkennung als auch für die Textgenerierung auf Wortebene. Für diese Schritte wurden zuvor CNN/RNN Modelle verwendet, jedoch weisen neue Transformer basierte Modelle eine höhere Texterkennungsgenauigkeit auf.
Die Software finden Sie hier.